How to structure content for AI visibility?
The ski-jump structure illustrates the way LLMs extract data from content.
It turns out large language models consume written content in a very similar way to humans, with one notable difference.
Which explains why ChatGPT pays vastly disproportionate attention to the top 30% of your content, as well as, to the end of it.
In my first job as a journalist for a leading newspaper (way before the Internet was invented), I was taught to write using “the inverted pyramid technique.”
The idea was to front-load stories with the most attention grabbing and interesting facts and then have the less important stuff lower down - because research showed most people only read the first few paragraphs.
New research into Large Language Models (LLMs) like ChatGPT suggests they are not dissimilar in their approach to consuming and analyzing content.
Except the optimal content structure for LLMs has more in common with a ski-ramp than an inverted pyramid.
This insight in based on an analysis of 1.2 million verified ChatGPT citations, as shared by SEO journalist Kevin Indig in his Growth Memo report on Substack.
How DO LLMs read content?
It’s explained by The Anatomy of the "Ski Ramp". The "Ski Ramp" refers to the disproportionate attention ChatGPT pays to the beginning of a content piece.
Because an LLM does not give equal weight to all parts of an article; instead, its interest "skis" downward as the word count increases.
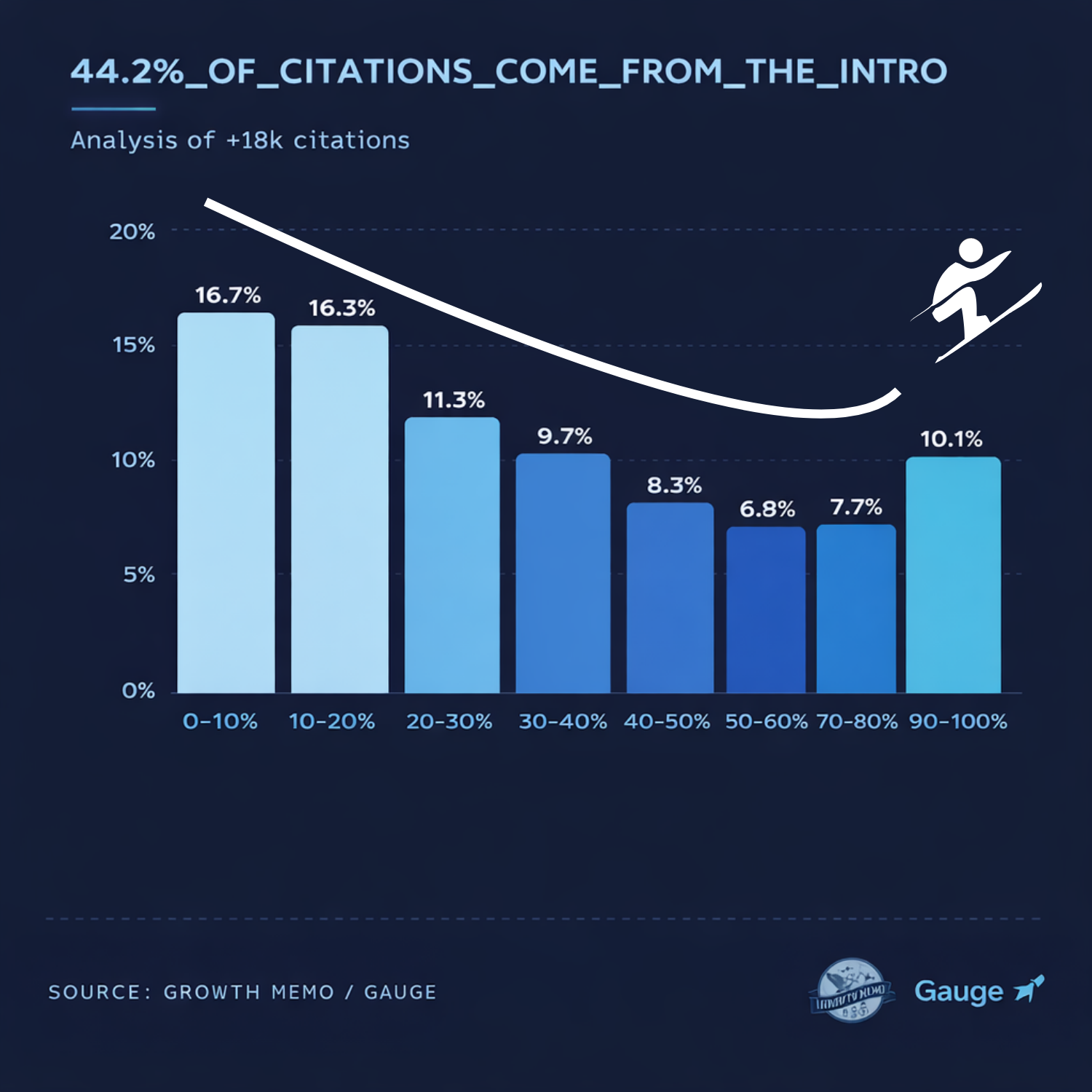
Where Citations Happen
The study analyzed 18,012 specific citations to map exactly where the AI pulls its information:
The Top (0–30% of text): This is the "high-yield" zone, accounting for 44.2% of all citations. The AI functions like a journalist, looking for the "Who, What, and Where" immediately.
The Middle (30–70% of text): Citation probability drops significantly here, accounting for 31.1%. If key insights are buried in the middle of a long post, they are 2.5 times less likely to be cited.
The End (70–100% of text): The AI "wakes up" for the conclusion, which accounts for 24.7% of citations. However, there is a total drop-off in the final 10%, meaning the AI ignores footers and legal disclaimers but loves "Summary" sections.
But how do LLMs scan individual paragraphs?
While the AI prefers the top of a page, it does not necessarily prefer the top of a paragraph.
Within a specific block of text, 53% of citations come from the middle of the paragraph.
This proves that ChatGPT reads deeply to find "information gain", the most complete and additive sentence, rather than just skimming the first line.
To maximize visibility, content creators should place their most information-dense paragraphs within the first 20% of the total page length.
What are the 5 characteristics of "citable" content?
Getting your facts in the right location is only half the battle when it comes to citable content.
The research identified five "Linguistic DNA" traits that make a specific "chunk" of text significantly more likely to be cited by an LLM.
1. Definitive language
Winning content is nearly twice as likely (36.2% vs 20.2%) to use definitive language.
Words like "is," "refers to," and "defined as" create strong "vector paths" in a database.
AI prefers "Zero-Shot" answers, sentences that resolve a query immediately, over complex narratives that require five paragraphs of synthesis.
The Shift: Move away from vague "In today's world..." intros and toward direct "X is Y" definitions.
2. Conversational "question-answer" structure
Text that includes a question mark is twice as likely to be cited.
Interestingly, 78.4% of these citations come from headings.
The strategy: Treat H2 tags as literal user prompts. Instead of a vague heading like "The History of SEO," use "When did SEO start?"
And be sure to use entity echoing: The answer should immediately repeat the keyword found in the header to anchor the AI's focus.
3. Entity richness
While standard English prose usually has an entity density (proper nouns like brands, people, or tools) of about 5–8%, heavily cited AI content has a density of 20.6%.
Why it works: LLMs are probabilistic. Specific names (e.g., "Salesforce" or "HubSpot") act as verifiable anchors that reduce "perplexity" (uncertainty) for the model.
Being specific, even mentioning competitors, increases the "bits" of information in a sentence, making it more attractive to the AI.
4. Balanced sentiment (The "Analyst Voice")
The AI avoids both "Pure Objectivity" (dry, 0.0 score) and "Pure Subjectivity" (emotional opinion, 1.0 score).
The winning "sweet spot" is a Subjectivity Score of 0.47.
The "Analyst Voice": This tone combines a verifiable fact with a brief analysis of how that fact applies. It isn't just "The iPhone 15 was released in 2023"; it’s "The iPhone 15 features an A16 chip, making it a superior choice for creators."
5. Business-grade writing
LLMs prefer clarity over academic complexity. "Winning" content typically scores a 16 on the Flesch-Kincaid scale (College level), whereas "losers" often score 19+ (PhD level).
Avoid paying “Clarity Tax”: Long, winding sentences with heavy jargon are difficult for the LLMs to extract facts from. The goal is "The Economist" style: sophisticated vocabulary but simple, direct subject-verb-object structures.
In summary: What is the ideal content structure for AI search?
The "Ski Ramp" structure reveals the importance of getting your main points across up-front.
AI algorithms interpret a "slow reveal" as a lack of confidence.
To win visibility in, content must function as a structured briefing that front-loads conclusions and uses high entity density.
Fortunately, this structure works for humans, too.
Just as the AI scans for the "Bottom Line Up Front" (BLUF), human readers also scan for quick insights.
By writing for the "Ski Ramp," you satisfy both the machine's architecture and the human's limited time.